1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| import cv2
import numpy as np
import mediapipe as mp
import pyautogui
from mss import mss
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
smile_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_smile.xml')
cap = cv2.VideoCapture(0)
sct = mss()
while True:
ret, img = cap.read()
sct_cap = np.array(sct.grab({"top": 0, "left": 0, "width": 1920, "height": 1080}))
faces = face_cascade.detectMultiScale(img, 1.3, 2)
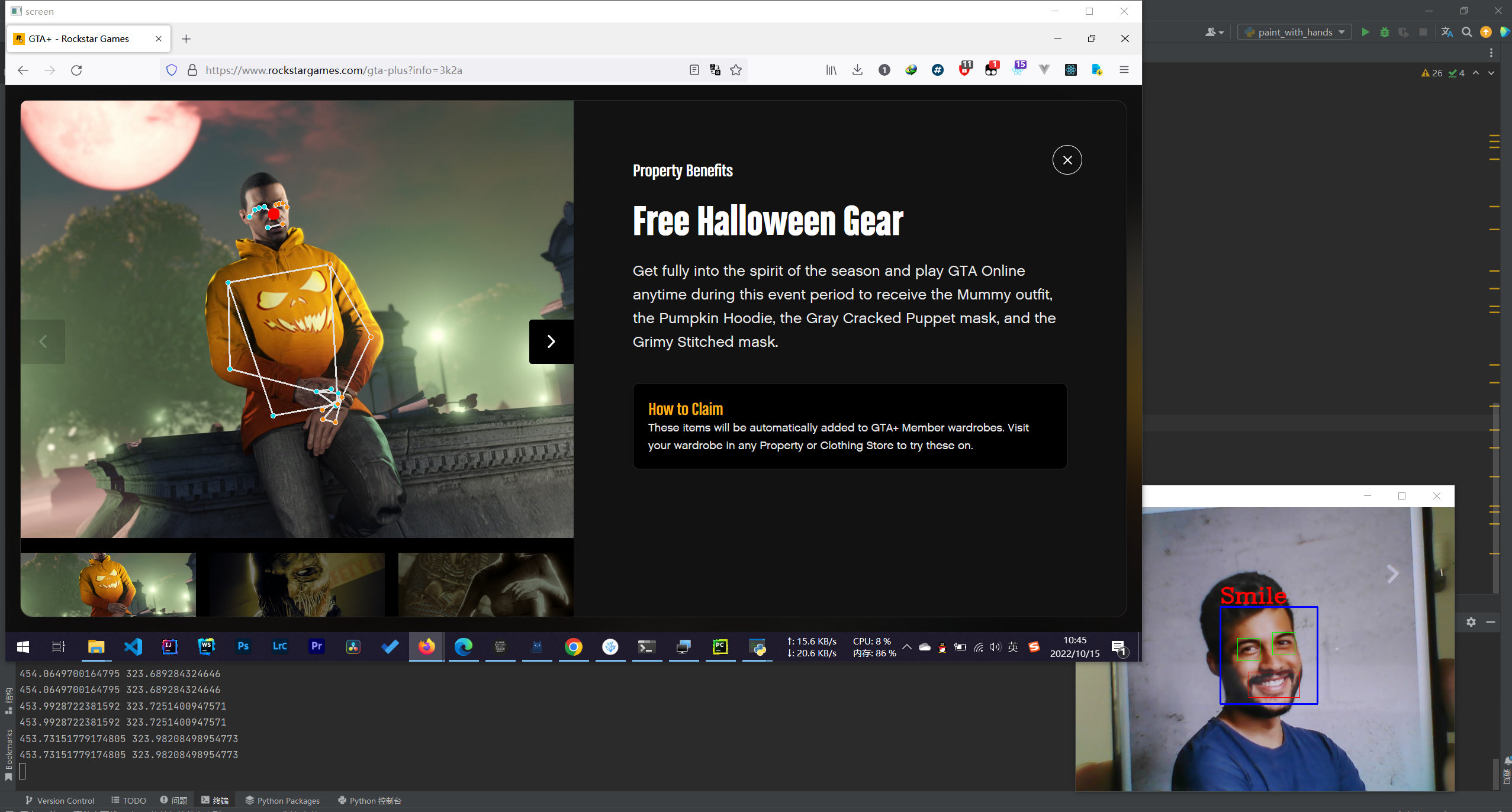
for (x, y, w, h) in faces:
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
face_area = img[y:y + h, x:x + w]
eyes = eye_cascade.detectMultiScale(face_area, 1.3, 10)
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(face_area, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 1)
smiles = smile_cascade.detectMultiScale(face_area, scaleFactor=1.16, minNeighbors=65, minSize=(25, 25),
flags=cv2.CASCADE_SCALE_IMAGE)
for (ex, ey, ew, eh) in smiles:
cv2.rectangle(face_area, (ex, ey), (ex + ew, ey + eh), (0, 0, 255), 1)
cv2.putText(img, 'Smile', (x, y - 7), 3, 1.2, (0, 0, 255), 2, cv2.LINE_AA)
if len(smiles) > 0:
pose = mp.solutions.pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
sct_cap.flags.writeable = False
sct_cap = cv2.cvtColor(sct_cap, cv2.COLOR_BGR2RGB)
results = pose.process(sct_cap)
sct_cap.flags.writeable = True
sct_cap = cv2.cvtColor(sct_cap, cv2.COLOR_RGB2BGR)
mp.solutions.drawing_utils.draw_landmarks(
sct_cap,
results.pose_landmarks,
mp.solutions.pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp.solutions.drawing_styles.get_default_pose_landmarks_style())
if results.pose_landmarks:
landmark = results.pose_landmarks.landmark[0]
x = sct_cap.shape[1] * landmark.x
y = sct_cap.shape[0] * landmark.y
print(x, y)
cv2.circle(sct_cap, (int(x), int(y)), 10, (0, 0, 255), -1)
pyautogui.moveTo(x, y)
cv2.imshow('frame2', img)
cv2.imshow('screen', sct_cap)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
|